在閱讀完文章的「Split Samples」段落後,該作者已經完成資料特徵的挑選以及分類成不同的集合。
筆者決定先用 pandas 的套件來看一下目前我們的資料可以給我們什麼樣的線索來預測。
首先讓我們先將 pandas 引入目前的 module:
import pandas as pd
接著讓我們把目前資料夾底下的 csv 檔讀進來:
data_file_path = 'prediction/annoyance_output_manual_for_predict.csv'
df = pd.read_csv(data_file_path)
此處的 df 為 pandas 的 dataframe 的縮寫。
要讓 .py 檔可以正確地被 IDE 解析,我們要設置 Python interpreter。讓我們在 vscode 按下 command + shift + p 開啟控制選單,輸入 interpreter 後可以看到 Python: Select Interpreter 的選項。點擊進去以後選擇你目前環境即可。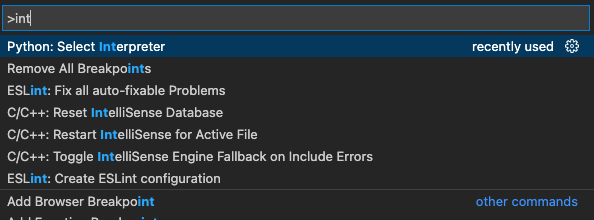

否則,你可能會看到類似這樣的提示訊息: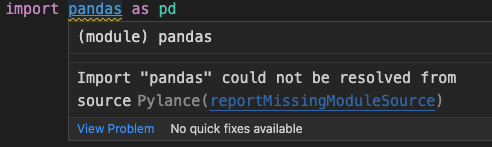
讓我們稍微把 df 印出來看看:
print(df)
然後在 terminal 輸入:
python prediction/predict.py
我們看前面幾行的結果,來思考一下接下來的方向: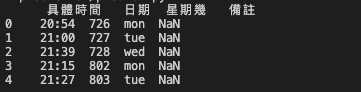
花了一些時間後,筆者大致有了實作預測的方向。若各位讀者先進有任何建議,再拜託告訴我。
我們最終是要預測每一天的發生時間,筆者猜想,每一天發生的時間基本上是基於該天的工作量。如果提早做完工作,那麼該人員下班的時間就會提前,關門就會提早發生,反之亦然。
而工作量的多寡取決於該天是星期幾,如果是週一到週四,那麼可能工作量會比較少,週五以及週末的工作量會比平常還要多的。
筆者查詢了該店家 Google Map 上的熱門時段,映證了筆者對於工作量的猜想。但與關門時間是否相關,就留待後續的驗證。
(雖然不喜歡甩門的行為,但畢竟非滔天大罪,在此為保護商譽,請恕筆者不提供截圖。)
所以筆者決定將星期幾作為分類,依照每一天預測各自的關門時間。
為了看到依照星期幾進行的分類的結果,讓我們使用 pandas groupby 的函數:
group_by_weekdays = df.groupby('星期幾')
print(group_by_weekdays.count())
.count() 會顯示各欄位的在該分類的值有幾個。
印出來後,首先筆者發現幾筆 thu 寫成 thur 的,原因是先前結構化沒有做好。
讓我們回去 dayTimeStructurize.js 加一個 TODO,之後回來處理這一段:
if (!!weekday) {
// 統一成全部小寫
const formattedWeekday = weekday.toLowerCase();
// TODO: 最後取前三位數,避免 thu 寫成 thur 仍會通過的情形
temp.push(formattedWeekday);
splittedStrArr = splittedStrArr.filter((element) => element !== weekday);
}
手動更改幾筆錯誤資料後,結果顯示如下: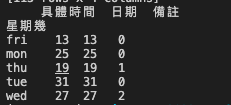
竟然沒有週六、週日的資料!
筆者推測原因可能有兩個:
讓我們明天繼續。今天收工!

